![]()
 212℃
212℃  李雨宸 发布时间:2020-11-03 16:39
李雨宸 发布时间:2020-11-03 16:39
接触过seo的小伙伴一定都知道robots的具体含义,但也有一些刚开始学习的伙伴对于网站robots究竟是什么意思还是一头雾水。那么,网站robots到底是什么呢?它又有哪些用途呢?在这篇文章中,我们将会向大家介绍网站robots的具体意义,它的用途、制作技巧、规律以及相关注意事项。

一、网站robots的含义和运作方式
网站robots是网站中的一个系统性文件,它位于域名根目录。网站robots的作用主要是在网络上抓取并索引内容,之后提供给信息搜索者。我们在搜索我们想要的内容时,为了能够迅速抓取到网站,搜索引擎会获取从一个网站到另一个网站的链接。
最终会获取到大量相关网站的链接,这种运作方式常常被称为“蜘蛛爬行”。网站robots会帮助我们抓取网络中的相关内容,也就是行内人常说的引导和控制蜘蛛爬行规则。
二、网站robots的主要作用
首先,如果网站不愿意公开相关内容,它可以禁止蜘蛛爬行,以便对相关内容进行充分的准备。
其次,可以禁止蜘蛛搜索一些对用户无意义的系统文件,如无关应用、脚本以及其他无关类型的代码,能够节省我们的搜索时间。另外,它还可以有效避免搜索引擎获取一些网站复制内容或是重复内容,最重要的是它可以屏蔽一些恶意蜘蛛。
如有时我们可能会不小心让一些搜索引擎抓取我们整个网站上的内容,这可能非常危险,但如果使用了网站robots,不仅会更安全也会十分方便。
三、做好网站robots的一些方法、技巧和规律
首先,我们需要强调一下网站robots文件的格式是.txt格式的,其他格式是无法做robots文件的。其次,robots文件的所有字母必须使用小写的格式,并将之存放在网站的根目录中。
另外,在制作网站robots时,User-agent、Allow、Disallow、Sitemap这些单词的首字母必须大写,后面的字母则需要使用小写格式。最重要的是——“:”后面的空格一定是在英文输入状态下的空格。例如:
User-agent:*——这里的“*”是一个通配符,代表的是所有搜索引擎的种类。
Disallow:/require/——所定义的是禁止蜘蛛搜索require目录下的内容。
Disallow:.jpg$——所定义的是禁止蜘蛛搜索网页中所有的jpg格式的照片。
Allow:.gif$——所定义的是允许蜘蛛搜索网页中的所有的gif格式的动态图片。
四、没有做好网站robots的弊端
如果没有做好robots文件,那么很大可能会浪费服务器资源,获取一些不必要的或是无意义的抓取内容,严重的话也会泄露客户资料中的私密信息,对网站或是公司都会带来不少的损失。
五、网站robots文件受到限制怎么办?
首先,我们需要把设置网站允许存在robots文件,改变robots的限制语法,解除蜘蛛的访问限制,之后再到网站站长的后台对robots文件进行检测并更新。网站站长后台在进行检测时往往会告诉我们抓取失败,这时不要急,我们再多抓取几次就会触发蜘蛛采取抓取站点的行动。
接着我们再申请上调蜘蛛抓取频率。除此之外,我们也要告知网站反馈中心这种情况的发生是由于不当操作导致的,而不是恶意操作。一系列步骤完成后,我们耐心等待蜘蛛来就好了。
网站robots文件的检测
百度搜索“robots检测 站长工具”(http://s.tool.chinaz.com/robots),输入待检测域名即可检测,如下图1-1所示。
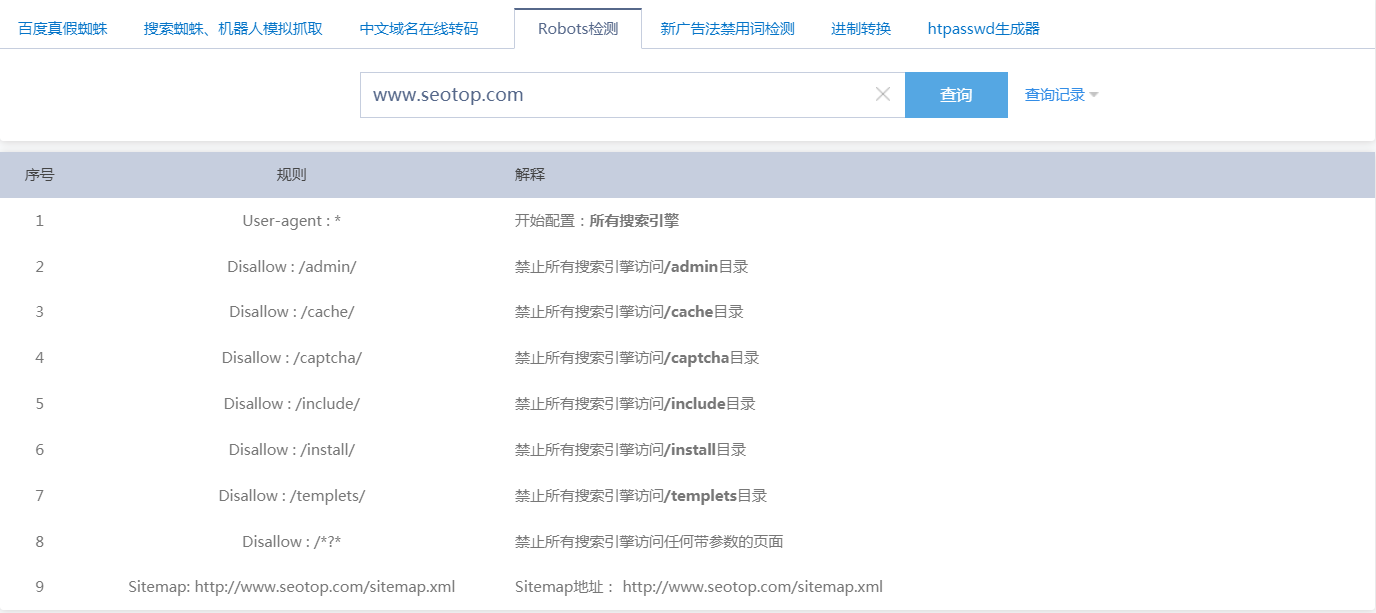
图1-1:robots文件检测
网站robots文件的生成
百度搜索“robots文件生成”(http://tool.chinaz.com/robots/),根据可视化选项即可生成robots内容,复制到.txt文本即可。如图1-2,图1-3所示。
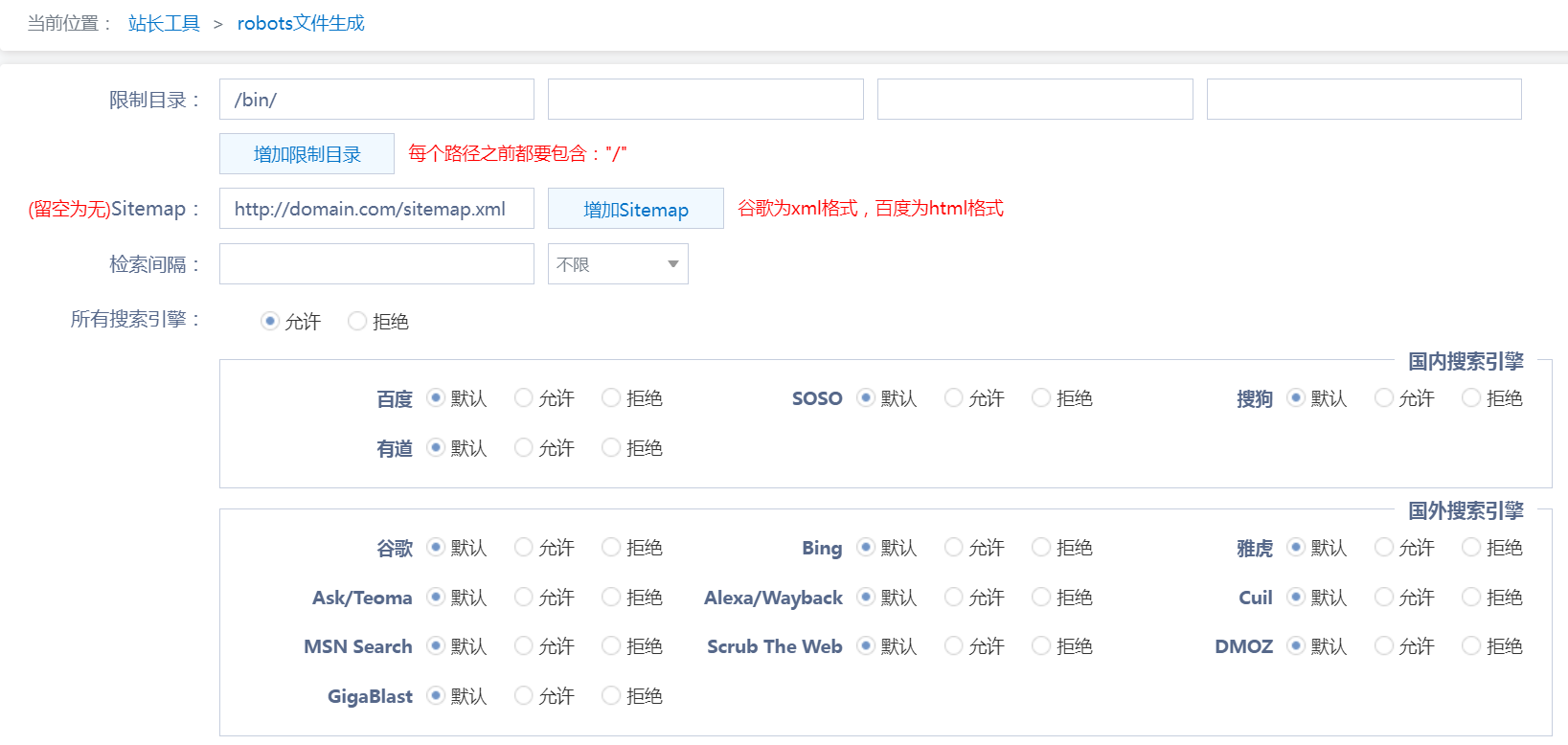
图1-2:可视化robots选项
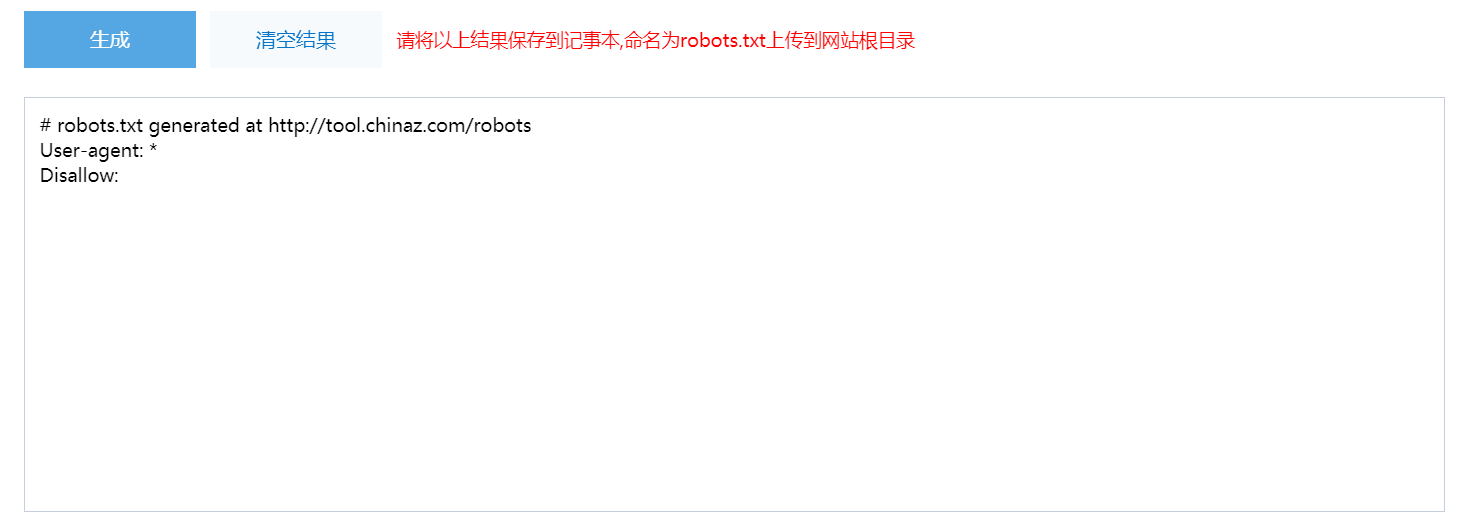
图1-3:生成的robots内容
网站robots与收录的关系
robots文件直接定义了网站允许和禁止访问的“蜘蛛”和页面,如果禁止了蜘蛛,那么搜索引擎不会收录网站的任何内容,如果允许蜘蛛爬行某些目录或者页面,那么蜘蛛可能会去爬取,但是不一定保证收录,因为这还和文章的内容质量等因素有关。
所以,robots文件会影响收录,但是并不是说有了robots文件一定能让你的网站有一个好的收录效果和排名。以上就是对网站robots文件的介绍,希望你能有所收获。
版权声明:本站原创,转载必究。
阅读原文:https://www.seotop.com/article/534.html

 Top推荐
Top推荐

